Autoencoder is a type of neural network that is used to reconstruct the given data. It works by learning the lower dimensional and compressed representations of data and is used to reconstruct the data. The data reconstructed have less noise compared to the input data. Autoencoder consists of two networks named as encoder and decoder networks to learn the representations from data. In these two networks, the number of neurons is increased (in the encoder) and then the number is decreased in the decoder network to reconstruct the data.
They are used in unsupervised machine learning for dimension reduction, feature extraction, anomaly detection, and image processing.
Understanding the Autoencoder
These types of neural networks are designed to learn the efficient representation of data and are widely used for data compression and anomaly detection. Encoder and decoder networks are combined to form the autoencoder. The description is given below:
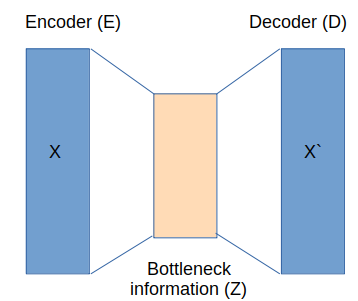
Encoder:
- The encoder network (E) compresses the input data (X) to a lower dimensional representation (Z) representing the useful features.
- The neurons in the layers of the encoder are reduced gradually.
- At the bottleneck layer, the dimensionality is significantly reduced and this layer represents the encodings of data.
Decoder:
- The Decoder network (D) takes the encoded data from the encoder and uses it to reconstruct the data.
- The neurons in the layers of the decoder are increased gradually and the last layer dimensions are the same as that of the first layer.
Training of autoencoder
The training involves updating the parameters to reduce the reconstruction loss. In the training process first, the input data (X) is encoded to latent representation (Z) using the encoder network (E) and then Z is used by the decoder network (D) to output the reconstructed data (X`). In equations, it can be represented as:
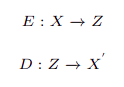
To construct an autoencoder following points are taken into account:
- To train an autoencoder it is important to consider the number of layers and number of neurons in these layers. The number of neurons in the bottleneck layer is particularly important as it captures the minimal essential information to reconstruct the data. If it has fewer neurons then the important information can be lost leading to decreased performance.
- Regarding the number of layers in the network a shallow network is used and it is best practice to use different architectures to select the one that works best for data.
- Mean squared error or L1 loss is used as the objective function that is optimized during the training.
Applications of Autoencoders
Image Denoising and Reconstruction:
Autoencoders can learn to denoise images by reconstructing clean versions from noisy inputs. Used in image compression techniques like JPEG to reduce file sizes while preserving visual quality.
Anomaly Detection:
- Autoencoders learn the normal patterns in data and can detect anomalies by identifying deviations from learned representations.
- Applied in cybersecurity for detecting network intrusions and in healthcare for identifying anomalous medical conditions.
Feature Extraction:
- Pre-trained autoencoder models can be used as feature extractors in downstream tasks like classification and clustering.
- Enables learning meaningful and compact representations of complex data.
Generative Modeling:
- Variational autoencoders (VAEs) are used in generative modeling to generate new data samples by sampling from the learned latent space distribution.
- Applied in generating realistic images, text, and other types of data.