Stop words are commonly used words in a language that are not very important and don’t contribute to understanding the NLP tasks. These words occur frequently in text and removing these words results in efficient processing and analysis. After tokenization, it is good to remove the stop words to increase efficiency and performance. This article provides an in-depth explanation of stop words, their impact on NLP tasks, and techniques for their removal.
What are the stop words?
Stop words are common words that carry little semantic meaning and occur frequently in a language. These words help with sentence structure and grammar but need to provide more information about the text’s subject or content.
They are typically functional words like
- articles (e.g., “the,” “a”)
- conjunctions (e.g., “and,” “but”)
- prepositions (e.g., “in,” “on”)
- pronouns (e.g., “he,” “she”)
Stop words act as noise in data and affect the relevance and accuracy of the NLP algorithm.
Need to remove the stop words
The removal of stop words depends on the specific task. If the aim is to classify the text the removal of these words is important. As these words occur more commonly in text their removal gives more importance to words that are important and less common for classification.
Example of Stop Word Removal
Let’s consider the sentence: “The quick brown fox jumps over the lazy dog.”
After the removal of stop words, the sentence becomes: “quick brown fox jumps lazy dog.”
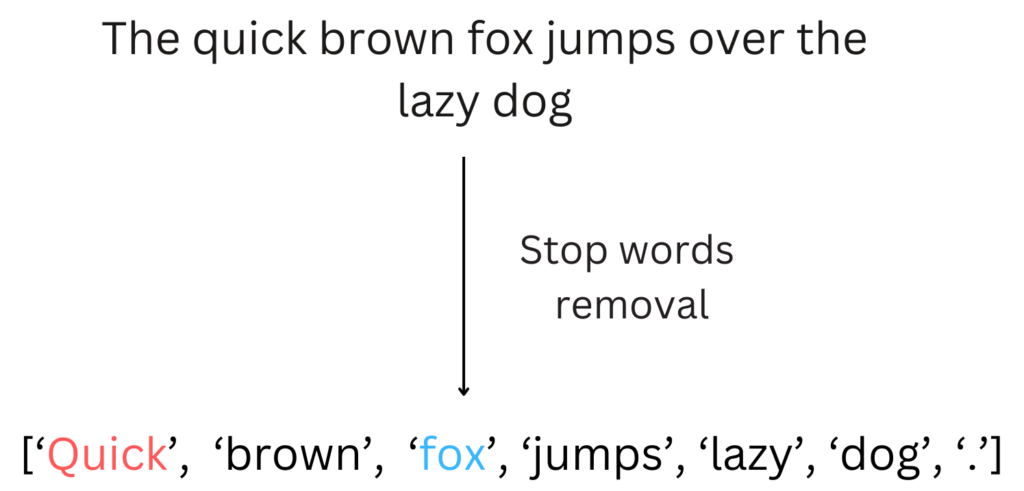
The removal of the words “the,” “over,” and “the” reduces noise and focuses on the content-specific words “quick,” “brown,” “fox,” “jumps,” “lazy,” and “dog.”
For tasks like machine translation and text summarization removal of these words is not recommended as they play an important role in these tasks.
Techniques for Stop Word Removal
Predefined Stop Word Lists:
In many NLP libraries, there are predefined lists of stop words for different languages. These lists can be used to remove the words from text. An example of NLTK is given below.
Custom Stop Word Lists:
For a specific domain or dataset stop word lists can be created by identifying frequent but non-informative words in that domain or dataset.
Manual Removal:
In some cases, manual inspection and removal of stop words may be necessary, especially for small datasets or specialized text corpora.
Removing Stop Words using NLTK Library
Here is an example of removing stop words from text using NLTK.
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# comment the line below if you haven't already downloaded the stopwords
nltk.download('stopwords')
nltk.download('punkt')
# Define the sentence
sentence = "The quick brown fox jumps over the lazy dog."
# Tokenize the sentence
words = word_tokenize(sentence)
# Get the list of stop words in English
stop_words = set(stopwords.words('english'))
# Filter out the stop words
filtered_sentence = [word for word in words if word.lower() not in stop_words]
print(filtered_sentence)
Output:
['quick', 'brown', 'fox', 'jumps', 'lazy', 'dog', '.']