This article explains the boosting and bagging methods used in machine learning. How both the methods work and what are their advantages are discussed here.
Boosting
Boosting is an ensemble learning technique in which a number of weak classifiers are trained sequentially and each classifier tries to reduce the error of its predecessor classifier.
- First, a model is trained on the entire dataset.
- A second model is trained which takes into account the errors of the first model and tries to reduce them.
- In the training of the second model, more weight is given to examples that were misclassified previously.
- This process continues either until the entire training data is correctly classified or until the specified maximum number of models is reached.
How does boosting work?
Boosting is a supervised machine-learning technique that combines multiple weak classifiers to improve performance. The algorithm consists of the following steps.
- Initial Model Training: A base model is trained on the entire training dataset. Every sample in the dataset is given equal weight.
- Error Evaluation: The model’s errors are evaluated, and the data points that were misclassified or predicted poorly are given more weight.
- Sequential Training: A new model is trained, focusing more on the previously misclassified data points. This process is repeated for a specified number of iterations.
- Weighted Aggregation: The final prediction is obtained by a weighted sum of the predictions from all the models, with more accurate models typically given higher weights.
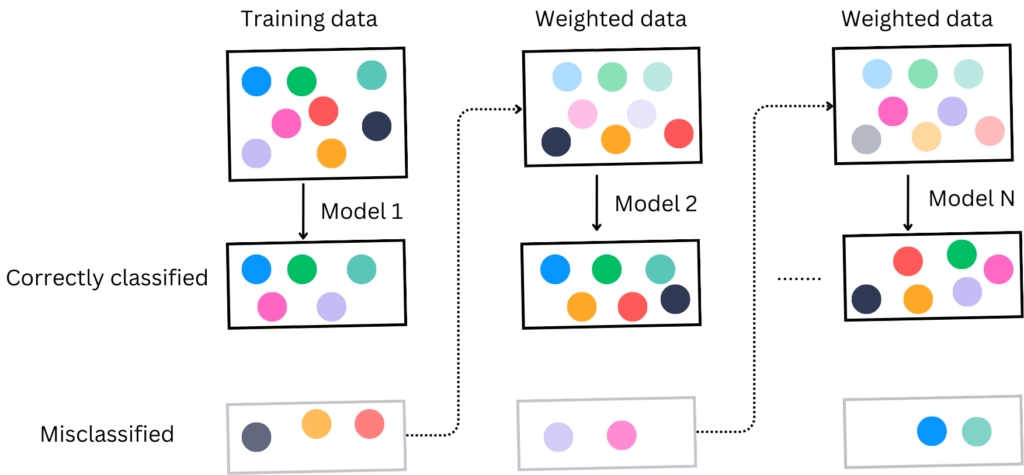
Using the above figure give the example: In the first step, the entire training dataset is used and the misclassified examples are identified. In the second model previously misclassified 3 examples are given more weight in training. The model correctly classified these examples and the error rate is calculated. The third classifier gives more weight to the samples that were misclassified by model 2. Model 3 correctly classifies the previously wrong examples. In the final step, all the models are combined for prediction increasing the performance compared to individual models.
Benefits of Boosting
- Reduction of Bias: Boosting can improve the accuracy of weak learners by sequentially focusing on the mistakes of the previous models.
- High Predictive Accuracy: Boosting often leads to superior performance compared to other methods because it reduces both bias and variance.
- Flexibility: Boosting can be applied to a wide variety of base learners, making it versatile for different types of data and problems.
Bagging
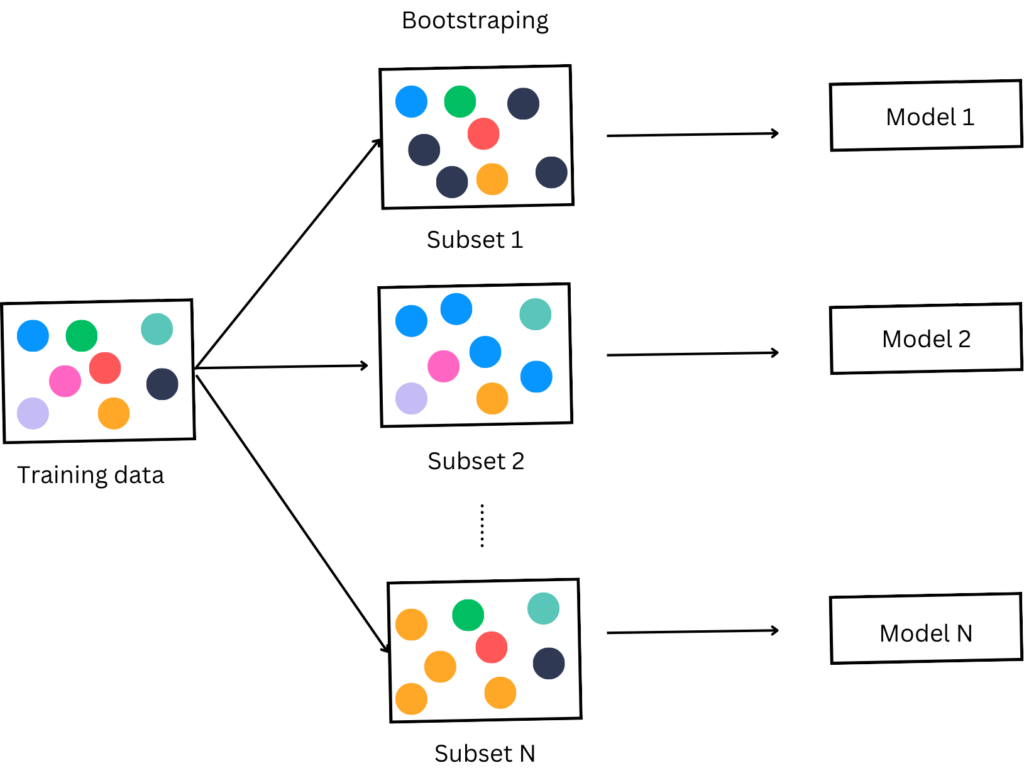
Bagging is a type of ensemble learning in which multiple models are trained in parallel using different subsets of data. The subset of data is selected using the bootstrap techniques in which samples are selected randomly from the training dataset.
Different models are trained using these subsets and decision is made using the majority voting technique.
How Bagging Works
- Data Sampling: From the original training set, multiple new training sets are created using bootstrapping, a method that involves random sampling with replacement.
- Model Training: Each of these new training sets is used to train a separate model of the same type.
- Aggregation: The predictions from all the individual models are aggregated. For regression tasks, this typically involves averaging the predictions, while for classification tasks, a majority vote is often used.
Benefits of Bagging
- Reduction of Overfitting: By averaging multiple models, bagging can significantly reduce the risk of overfitting.
- Improved Accuracy: Bagging can lead to better performance by reducing variance and providing a more stable prediction.
- Parallel Training: Models in bagging are trained independently, allowing for parallel processing and faster training times.